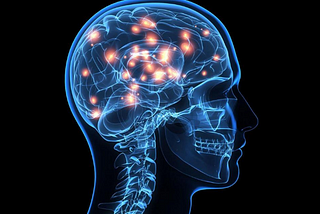
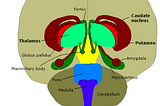
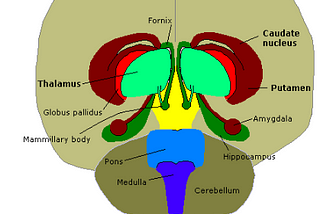
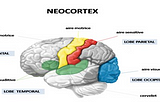
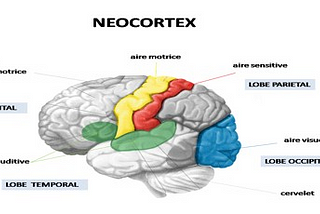
AbbyNeuromarketing : Tools &TechniquesGerry Zaltman from Harvard believes 95% of the human thinking and decision making takes place subconsciously mostly in the deep structures…3 min read·May 16, 2022----
AbbyKnow your Brain : Myths and factsMyth: Older people are doomed to forget things3 min read·May 12, 2022----
AbbyKnow your BrainA typical human brain comprises about 2 to 2.5% of the total body weight. However the brain uses up 20% of the total energy and O2 intake.2 min read·May 10, 2022--1--1
AbbyBrain and EmotionThe question must have fascinated everyone? A very simple question — how and why does Emotions come from? The question can be looked from…7 min read·Mar 21, 2022----
AbbyLiar BrainA popular belief is that liars avoid eye contacts, however there are series of scientific experiments to prove the contrary. Scientists in…2 min read·Mar 21, 2022----
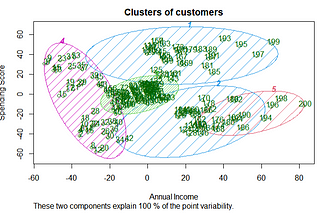
AbbyClusteringClustering is generally techniques for finding subgroups, or clusters in a given dataset. When we cluster the observations of a data set…5 min read·Jun 11, 2021----
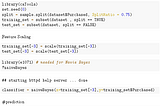
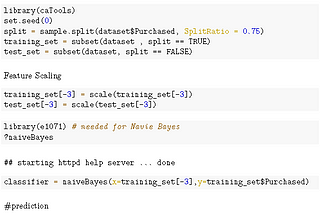
AbbyClassification.We all know, linear regression is for qualitative scenarios and when the response is categorical we go for classification. As the name…8 min read·Jun 4, 2021----